4 Jun 2025
GPU power management is a work in progress
 Max Smolaks
Max Smolaks
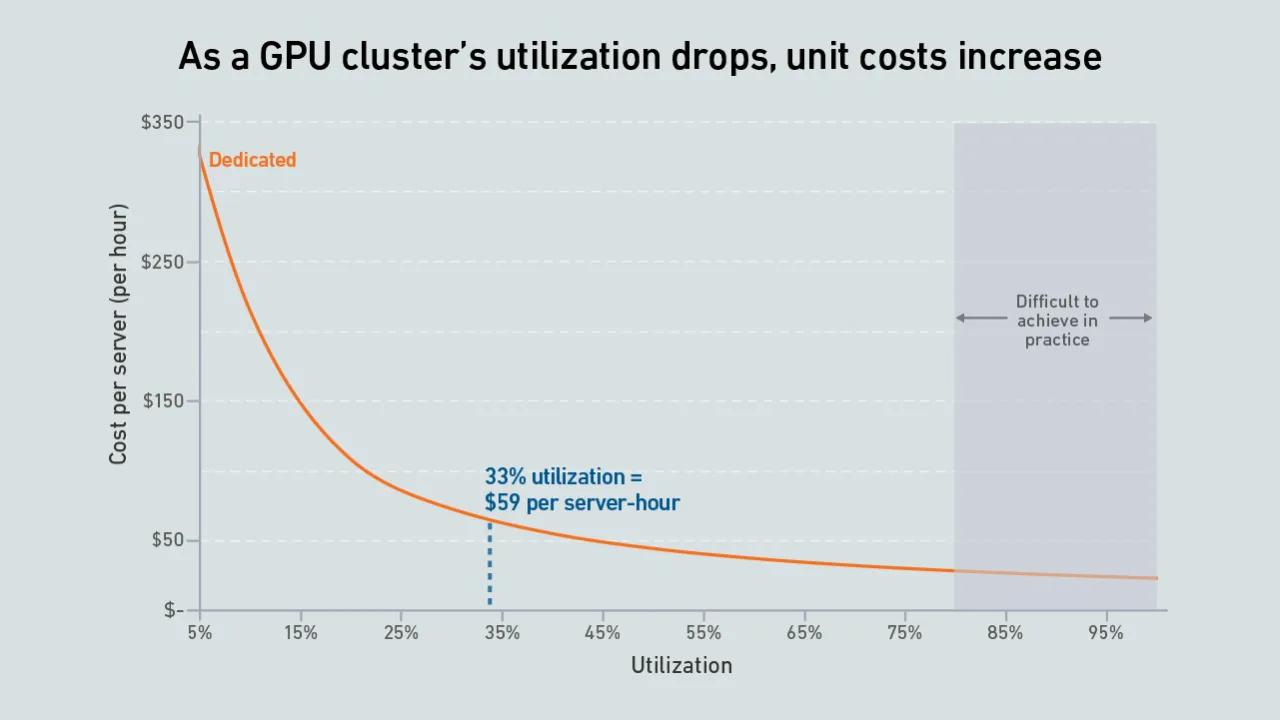
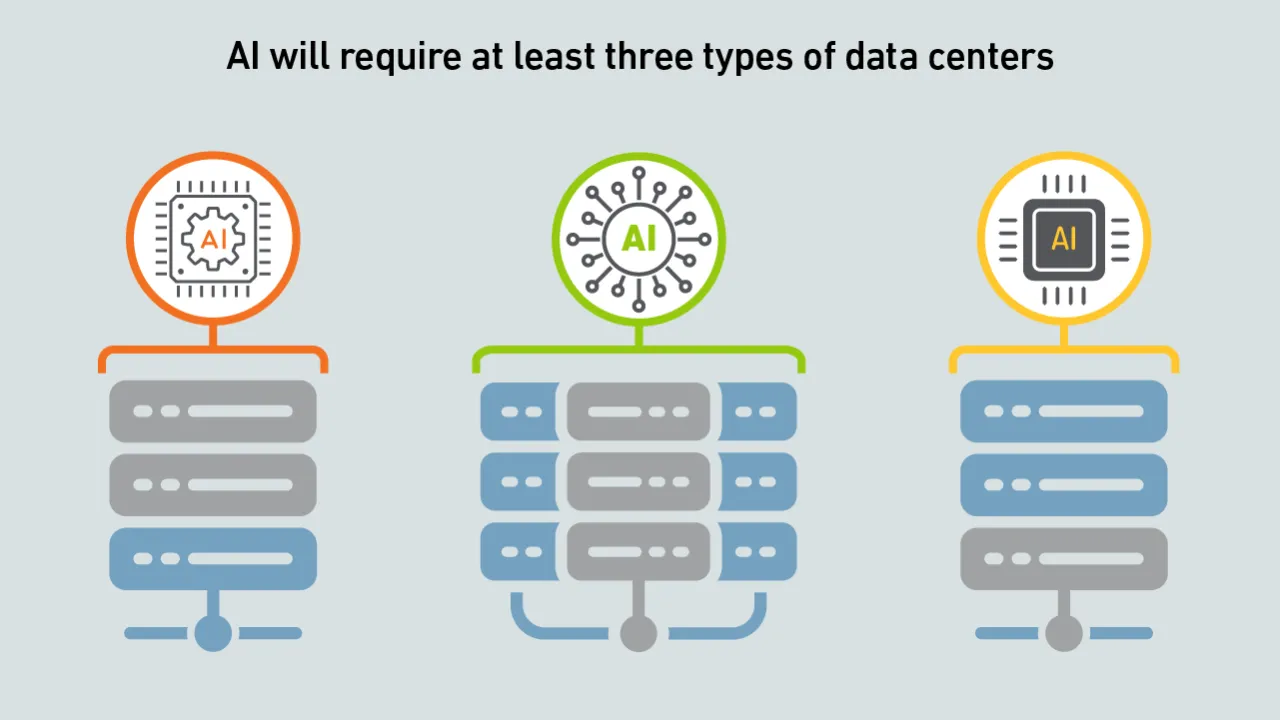
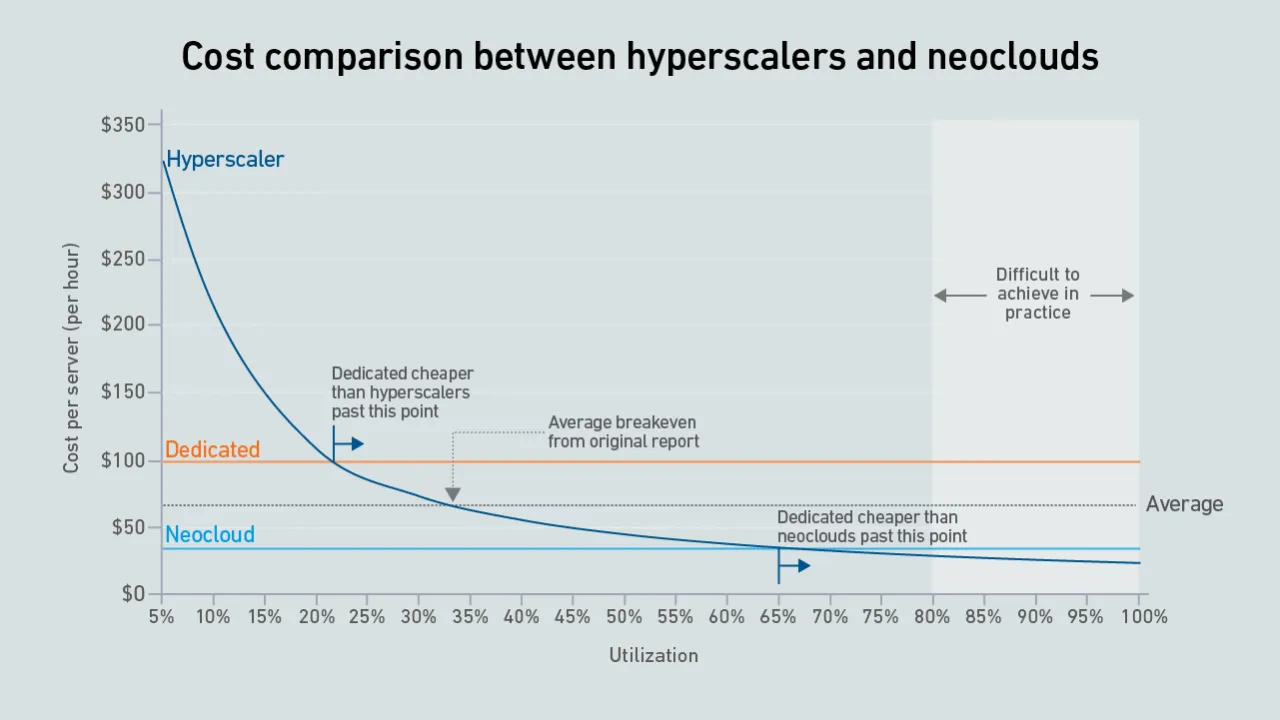
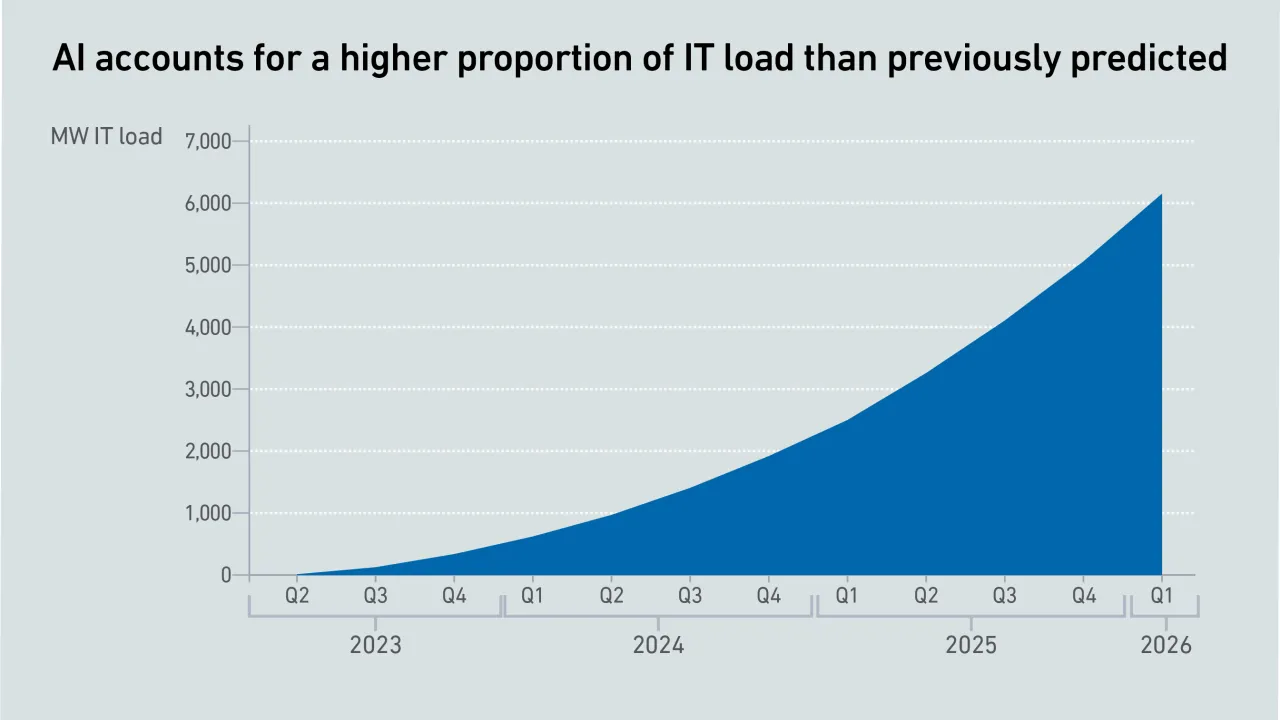
Today, GPU designers pursue outright performance over power efficiency. This is a challenge for inference workloads that prize efficient token generation. GPU power management features can help, but require more attention.

 Daniel Bizo
Daniel Bizo
 Dr. Owen Rogers
Dr. Owen Rogers


 Peter Judge
Peter Judge


 John O'Brien
John O'Brien

 Dr. Tomas Rahkonen
Dr. Tomas Rahkonen