3 days ago
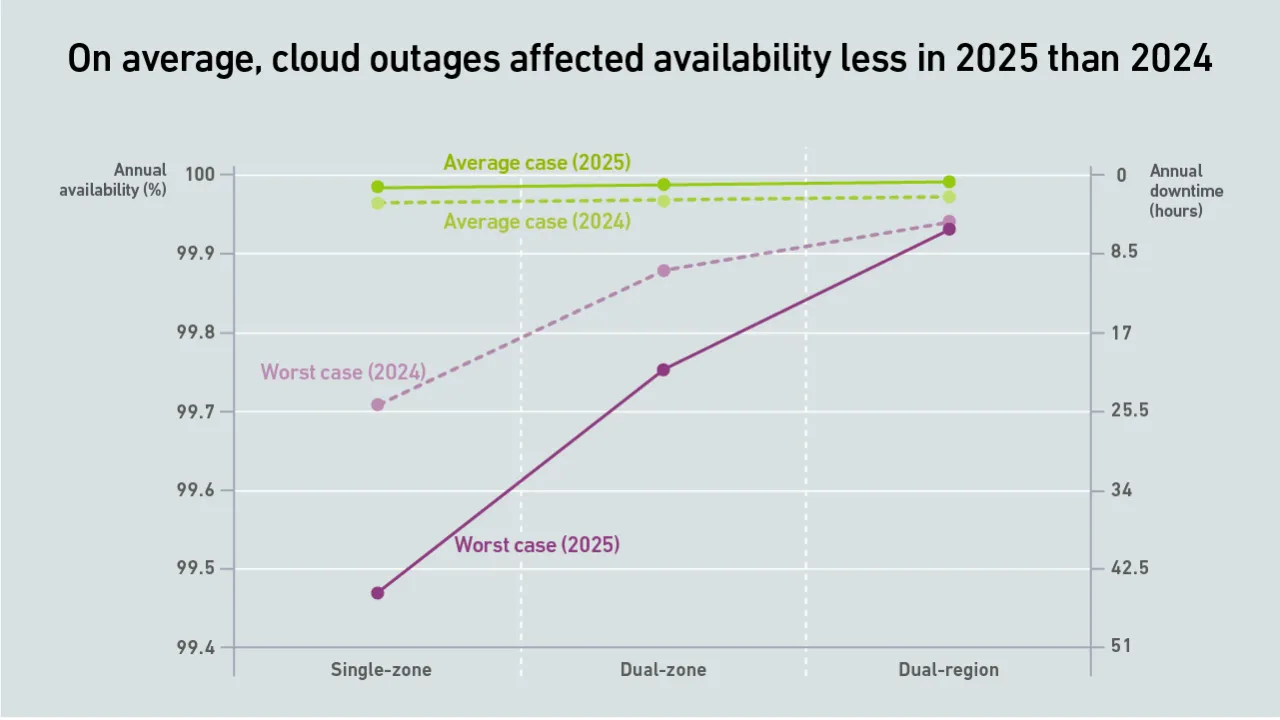
Cloud availability improved in 2025 — but worst cases worsen
On average, cloud provider outages affected application availability less in 2025 than in 2024. Yet risk remains: an unfortunate choice of zone or region can subject even well-planned applications to hours of disruption.